 In this article we look deeper into PDF documents creation and editing process. As we mentioned in “OCR: make your documents text-searchable” post, OCR process runs in multiple threads. The number of threads is equal to the number of CPU cores and each thread processes one page at a time. The time that OCR process takes for one page depends on multiple factors, such as page content, model of CPU and its utilization by other applications.
In this article we look deeper into PDF documents creation and editing process. As we mentioned in “OCR: make your documents text-searchable” post, OCR process runs in multiple threads. The number of threads is equal to the number of CPU cores and each thread processes one page at a time. The time that OCR process takes for one page depends on multiple factors, such as page content, model of CPU and its utilization by other applications.
OCR: Make Your Documents Text-Searchable
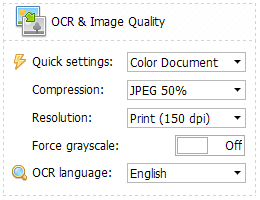 Optical character recognition (OCR) is now available in TaxWorkFlow. This tool allows you to convert scanned paper data records to text. This technology is being developed and enhanced for 30+ years and nowadays it works perfectly with electronic documents. You can read more about it in Wikipedia.
Optical character recognition (OCR) is now available in TaxWorkFlow. This tool allows you to convert scanned paper data records to text. This technology is being developed and enhanced for 30+ years and nowadays it works perfectly with electronic documents. You can read more about it in Wikipedia.
So what are the benefits of this technology?
TaxWorkFlow PDF Creator
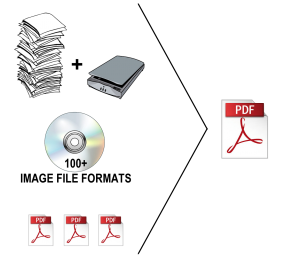 Another new feature in TaxWorkFlow is an ability to create PDF documents right within the TaxWorkFlow application. You can compose documents from different sources, such as:
Another new feature in TaxWorkFlow is an ability to create PDF documents right within the TaxWorkFlow application. You can compose documents from different sources, such as:
- Images captured from your scanner
- Images stored on your local disk (100+ formats supported including multi-page images, such as TIFF, MNG, JXR etc)
- Paste image from the clipboard
- Add existing PDF file as a part of new PDF document (each page of the original PDF file will be rasterized)
TaxWorkFlow PDF Viewer
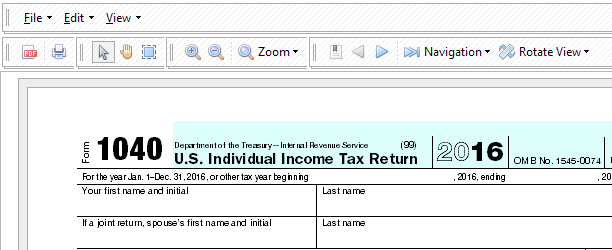
We are happy to announce a major document management system enhancement: a built-in PDF viewer that allows users to view PDF documents directly from TaxWorkFlow application. You do not need Adobe PDF Reader or any other third party PDF viewer anymore to be able to view PDF on your computer. Click on any PDF file from your database and it will be automatically opened inside the application.